| The Integrity Papers | Genre Heiner Benking US Website |


1993 American Institute of Physics
As part of the 1992 International Space Year (ISY), a one-time international conference devoted solely to Earth and Space Science Information Systems (ESSIS) took place at the Pasadena Convention Ctr, Pasadena, California, U.S.A, February 10-13, 1992. This conference promoted and enhanced inter- national scientific communication and cooperation for the collection, processing, archiving, distribution, and analysis of Earth and Space Science Data. This goal was accomplished by discussions among re- searchers and information system developers from the international space science community. The role of information systems in international cooperation and in education and outreach were topics of special interest.
Harmonization of Environmental
Meta-Information
with a Thesaurus-based multi-lingual and multi-medial Information
System
Heiner Benking*, Dr. Ulrich Kampffmeyer*
PROJECT CONSULT GmbH
Isestraße 63, W- 2000 Hamburg 13
Germany
* The authors are active as consultants in the framework of the HEMIS project of UNEP/HEM at Munich, Germany. The paper presents the actual state of the project and system design, but is subject to the ongoing development regarding further user requirements, new design considerations and the expert group recommendations. For the general scope, context and details of the project see /8-11/, in particular /12/.
Abstract
The availability and quality of standardized meta-information is the key for accessing the
huge masses of raw data stored in files and databases world-wide. The HEMIS project is
carried out by UNEP/HEM, Munich, Germany, for the harmonization of environmental
information. This paper describes one of the main aspects of the design considerations for
the HEMIS meta-database and information system. The system approach is based on multimedia
information accessable by a database and hyper-media program. The tool for harmonization
and standardized access is a multi-lingual thesaurus.
Introduction
The fundamental prerequisite for effective action to combat environmental problems is
reliable, comparable, actual and complete information. A vast amount of data is being
created in a wide range of environmental programmes and projects. The world-wide exchange
of environmental information is hindered by the lack of compatibility and the difficulties
bridging terminologies, languages and different quality standards. A possible solution for
the harmonization of environmental information for a world-wide scientific community is a
standardized thesaurus-based information system that offers access to trans-cultural,
cross-sectoral, and multi-dimensional information at low cost.
The Harmonization of Environmental Measurement project (HEM) was established by UNEP under the auspices of the Global Environmental Monitoring System (GEMS) as a part of EARTHWATCH according to the Environmental Experts of the Economic Summit EEES recommendations /11. Harmonization between programmes is a central goal for the future. One activity area of the HEM office is concerned with the collection and dissemination of information about available data and the implementation of global environmental meta-database and information system (HEMIS) capable of referencing, navigating, and linking multi-compartmental environmental information repositories. The international mandate and the demand for meta-information at a low cost led in 1990 to the design of HEMIS 12-71.
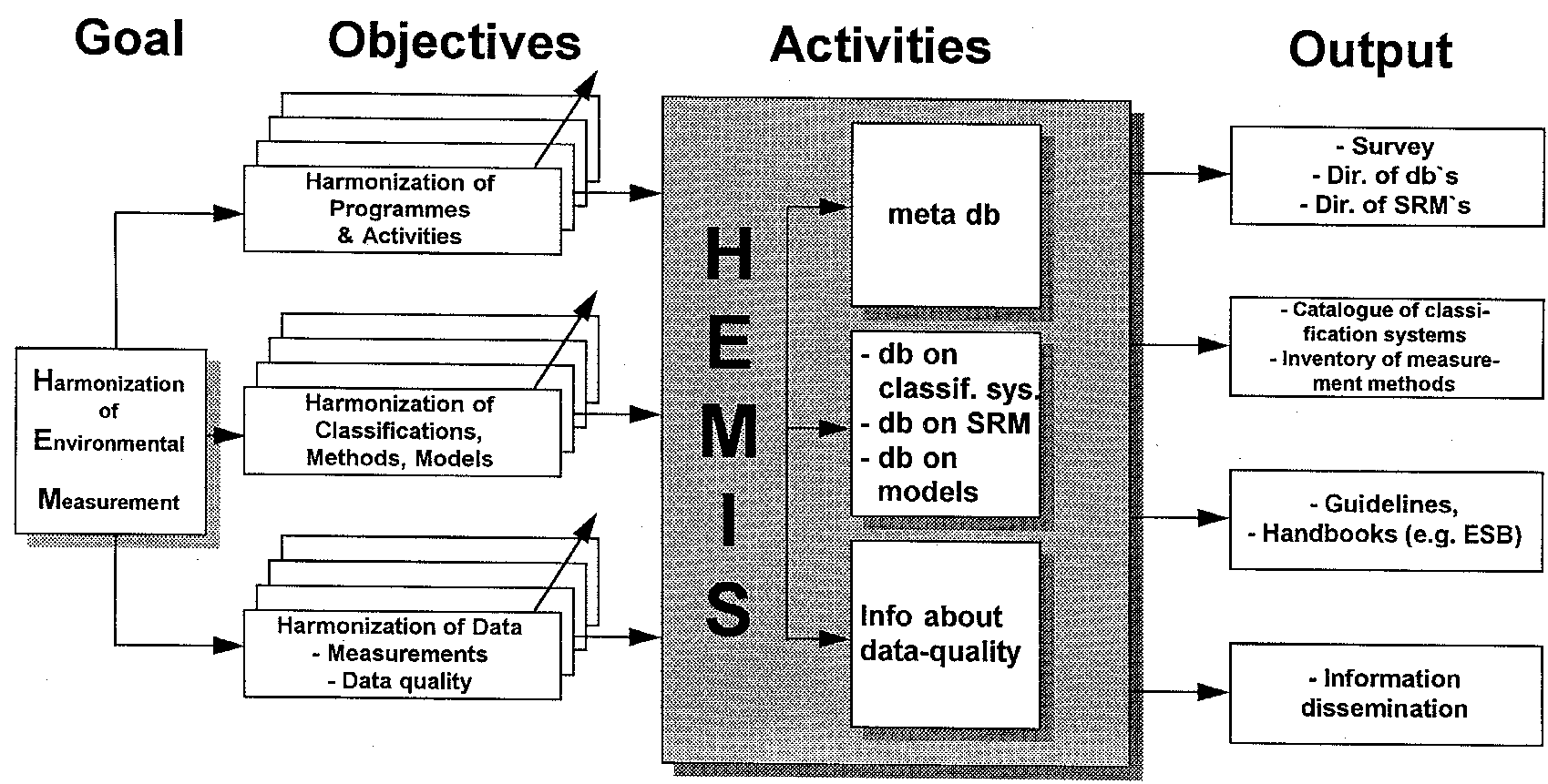
Fig. 1 HEMIS Goals, Objectives, Activities and Output.
The current design includes the following subjects as contents of the HEMIS:
- Reference information on environmental databases and information systems
- Reference information on environmentally active organizations and instututions
- Reference information on monitoring and assessment programmes of the above mentioned institutions
- Equipment and methods used in environmental measurement
- Standard reference materials (CRM) and their producers
- Reference information on models in use for analysing environmental data
- Reference information and samples of classification systems related to the environmental sciences.
Most of the information will be reference information to existing data sources. The standard reference material and related methods will be original information and data to harmonize as well as the qathering of environmental data.
Project Scope and Thesaurus Program Design Considerations
Environmental data is available from numerous sources, in different quality, in huge
quantity and sometimes even unknown to public and scientific community. The main task is
to allow access to original data with a standardized meta-database & information
system. A metadatabase only gives a reference, where original data may be found and how to
access it. A meta-information system aggregates the basic information about the contents,
quality, the used methods, publications, program and accessibility of the original data on
a higher level. The main task is to allow a definite access - a problem of nomenclature
and standardization.
There is no chance to harmonize, structure and standardise the nomenclature and data already existing in environmental science in regard of hundreds of institutes, whose information shall be incorporated in the HEMIS system. The only chance is the harmonization on the user side allowing easy access to information of different sources, structure and quality by standardized access methods. Therefore the HEMIS THESAURUS is a main aspect of the HEMIS system. The scientific community is used to English as main communication language. To open an information system to a broader public, to allow access to people from administrations, business companies, public, environmental groups and others, a multilingual thesaurus with a translation function is essential. The missing knowledge about databases and their contents of these groups of users can be bridged by an access method using their native language and colloquial expressions to guide via the translation and interpretation functionality of the thesaurus first to the correct scientific keyword and via this to the referenced meta-information.
The thesaurus is a structure lying as a multi-dimensional selection list behind a database entry or retrieval field. The HEMIS database model contains different types of fields like numeric, alphanumeric, date and other. The selection lists and the thesaurus avoid typing errors and allow standardized access to the information stored. In fact there are several thesaurus fields going to be implemented - for the list of continents and countries, biotopes and geographical zones i.e. These small thesauri will have a two or maximum three hierarchical layer structure. The most important thesaurus is the thesaurus of topics and subject keywords which will be implemented in a four or five layers structure including ignore than two thousand main entries. The interactive task of the thesaurus is guiding the user through a set of keywords for accessing data and information. The second task as a tool is to analyse and structure information delivered as ASCII file from associated institutes of the HEMIS project. A prerequisite is to create a classification and standardization scheme of the used descriptors and to implement a transformation program for the integration of the descriptors and their related data sets into the HEMIS database.
The system will use a graphic user interface for easy access. The user interface and the thesaurus contents can be switched from one language to another by a simple mouse click. The original design concept of the thesaurus was based on an multi-lingual information system used by the "wf - Gesellschaft zur Förderung der Schweizer Wirtschaft" (association for business development in Switzerland) which is installed at 4 different locations throughout Switzerland, connected via ISDN communication network and storing image and data information on optical disks. The thesaurus will use a standard database (SQL) as basis. The front end represented the contents of database fields to the user as a standard hierarchical thesaurus structure defined in the ISO standard. Internally the thesaurus is organized as network, which is only represented on the screen and as printout in a hierarchical order.
Different keyword entries in a selection list may occur on different hierarchical
levels due to their meaning in different scientific contents. The hierarchy is mainly used
for the visual organization of the keywords, which helps the user to navigate through the
data. Due to the network structure and the possibility to link keywords uni- and
bi-directionally the same keyword may occur several times at different positions in the
thesaurus list representation. For example the separation into the main classes chemistry,
soil science and physics in a thesaurus structure may lead on different levels to the same
keyword (i.e. "water").
The HEMIS is based on a reference model. The thesaurus transforms all input to a unique identifier. The descriptor database contains only the references between the unique identifiers and the related object identifiers. The object access database contains the logical and physical address information of the documents. The HEMIS will therefore include different databases and a information management system for the media used (object access database). The thesaurus and the descriptor database will be relational program systems available as standard product. The stored information (dataset, text file, image etc.) are objects (referred as documents), which are linked via unique document identifier with the descriptors of the descriptor database.
The Thesaurus Structure
The unique identifier (A) is used for accessing the reference database (Fig. 2). The HEMIS
thesaurus is designed as multi-dimensional structure. Thesaurus data sets in different
tables ("Slices") point to the same unique bentifier (Fig. 3). The logical
position of a keyword in the thesaurus structure is defined in the network of one or more
predecessors (B) and a number of following sub-class descriptors (C). The network allows
uni- and bi-directional links. This structure is independend from the hierarchical level
of original hierarchical position of the predecessors and successors. The selection list
on a lower hierarchical level is individually created regarding the entries marked on the
higher level and the previous entries which led to the current position in the thesaurus
network.

The main descriptor (D) is the keyword, which will be displayed inside a multiple selection list, when the thesaurus is used for retrieval. The position in the hierarchy (E) defines at which level of the hierarchical ordering the key- word originally was situated (in the paper based standard hierarchical structure) and where it shall be displayed using a tree overview function.
The following field in the thesaurus data set (F) contains a list synonyms, homonyms, abbreviations, plurals, latin definition, chemical formulas, acronyms a.s.o. This feature allows to connect with one keyword all definitions, which may be used in a similar context or with slight differences by other scientists. Keywords, which are not used in the restricted "main thesaurus" can be integrated without loss of information in this "synonym" field. The harmon- ization effect using the thesaurus for access is to lead the user by the standardized main keywords also to infor- mation which was originally described with other keywords or in another context. The additional keywords are not displayed in the thesaurus hierarchical structure but are retrievable by a global search (see below). The last field (G) is used to include a text explanation which is displayed as context oriented help function. This offers the possibility to give a detailed explanation how a keyword is defined and used.
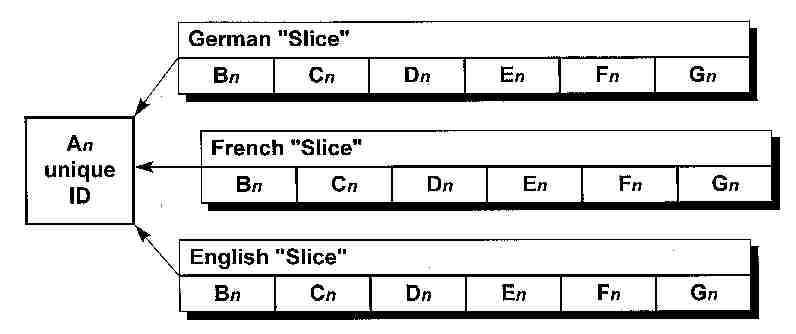
Fig. 3 The Keywords and their related Information in each "Slice" point to the same Unique Identifier (ID). Only the ID is used for Retrieval in the Database. The Thesaurus acts as a Pre-Processor.
All information in a "language slice" (fig. 3) may vary in detail to the basic version. This includes the ranking in the hierarchy, predecessors and followers, number and meaning of synonyms etc. In this way the thesaurus is not only a translated structure but an interpretation which fits to the differences of the languages and nomenclatures used. This structure allows to develop different slices of the thesaurus seperatly by different partner institutes. UNEP HEM once defines the "main descriptors" and the basic structure. The partner institutes then translate this structure into their native languages or interprete it using their scientific nomenclature. This may even lead to several "slices" in the same language but with a different scientific terminology. The structure as a net will allow the co-operating institute as well to add new categories and main descriptors without changing the structure. UNEP HEM will use to create the main thesaurus entries existing thesaurii which are already in use in environmental science (e.g. INFOTERRA, NASA Master Directory and others). These may be enlarged by the partner institutes in deeper hierarchy levels. For example, if UNEP chooses to create a hierarchy with four levels depth, partner institutes may add a fifth or sixth level in their language slice to give more details on special subjects. As well they may address their requirements to UNEP HEM for additional main keywords, which will be added by UNEP HEM within further releases.
The Use of the Interactive Thesaurus
The HEMIS uses a multilingual object oriented user interface. When the user
starts a retrieval operation in the HEMIS, he may choose for primary access three methods:
The global search facility is field independent. It acts as OBE (Query by Example). The
user types in the keyword he is looking for (using as well wild card and truncation
facilities). A box opens demanding him to specify, if he wants to
- search only in the thesaurus field and only with the main keywords of the language
- slice in use
- search as well in the synonyms, acronyms a.s.o of the language slice in use
- search as well in the help texts of the language slice in use (including hypertext features)
- search as well in the thesaurus field an only with the main keywords of other
- language slices when available
- search as well in the synonyms, acronyms of other language slices when available
- search as well in the help texts of other slices when available
- search in all other fields of the database (not only in the field with the thesaurus
- structure - this will take "some" time) of the language slice in use
- search in all fields of the database and in all language slices in use (this will take quite a lot" of time)
It any option is choosen the program will display that the retrieval will take more or less time. The global search takes at least more time than a search in the thesaurus mode. The user may use as well left hand truncation and / or wildcards. The retrieval leads to an hitlist and the main keyword is displayed. Now the user may choose to select one or more objects (see database stnucture below) for display or print. He may as well refine his request changing in the thesaurus mode (see below). If too many entries are found the program changes automatically to the refinement mode using the thesaurus.
The thesaurus supported retrieval is an easy to use method. The user may open the thesaurus window on its first level by mouse or keyboard action. He is allowed to choose one or more keywords from the displayed list. A new window aside opens displaying the next level of hierarchy. If two or more keywords were chosen on the predecessing level, a mixed list of all keywords is generated displaying all keywords belonging to all chosen primary keywords. From the second level he may choose as well one or more entries displayed which lead to a third selection list or he may start the retrieval process. To start a retrieval action is only allowed from the second or one of the following levels to avoid too long hitlists. From the second level on he may use as well the global search field for refinement purposes which is than used in an "AND" mode only. If more than one keyword is chosen the user may indicate if he wants to search in an "AND" or "OR" combination.
A third way of accessing information is a document-oriented hypertext facility which
leads from one document to another via individual links. This method requires no further
database retrieval if one document with a hyperlink is found and the links lead from one
document to others in a "quided tour".
The HEMIS Implementation - Status and Outlook
The implementation of HEMIS is proposed in two phases. In phase 1 HEMIS will include
mostly scanned facsimile information and files produced by UNEP HEM, due to the fact that
data are not available from partners at once and have to be prepared for the first
integration. These informations are manually indexed for access via the database. The
manual indexing takes a lot of time but is necessary to develop and optimize the thesaurus
in regard to the user needs. The first stage is mainly to demonstrate the use of HEMIS to
information deliverers, users and potential sponsor. When the sponsor for the production
of a CD-ROM is selected, a first demo disk with the harmonization thesaurus will be
produced. Phase 1 will take about one year. This phase is as well to be understood for the
production of the thesaurus language versions, the creation of the network of partners and
the system optimization.
Phase 2 starts paralel to phase 1. In this stage files delivered by partner institutes
will be analysed, the transformation of file formats and keywords via the HEMIS THESAURUS
will be improved to integrate the data step by step into HEMIS. This leads to individual
automatic indexing modules for HEMIS that allow after the first integration to interpret
and integrate data arriving in the same format automatcally into HEMIS.
As pure ASCII data (coded information) needs not so much storage space as facsimile image
information, n will replace corresponding facsimiles step by step. On each edition of the
CD-ROM more space for data will be available. The work for manual indexing will decrease
permanently. The ideal CD-ROM volume consists of 90% data coming from partners and 10%
additional explaining graphics, images, charts, maps i.e.
A first prototype was installed in 1991 using files and facsimiles from UNEP/HEM reports.
The prototype is based on the standard software HYPARCHIV, an optical filing and image
database program. It was choosen for the first prototype because 'n has already some of
the features required by the design of the HEMIS (low price, using Microsoft Windows as
user interface, multi-lingual access, hyper-links, storage of images, texts, graphics
a.s.o., multiple selection lists of keywords, EDITOR for the creation of databases and of
selection lists a.s.o.) The prototype lacks of the recommended thesaurus functionality.
The implementation of the thesaurus program of HEMIS will depend mainly on the acceptance
and the co-operation of the scientific community of institutes active in environmental
research. As well the discussion of including other information sources like geo-reference
data, maps i.e. is still going on.
References
/1/ EEES Reports - Environmental Experts of the Economic Summit - Report on
Current International Scientific Activities in improvement and Hammonization of Techniques
and Practices of Environmental Measurement - Report on Priority Areas for Improvement and
Harmonization..., - Report - Ensuring Continuing Progress in Improvement and Harmonization
..., GSF-PFU Secretariat, Munich, FRG- Meeting, December 1986. Final Report June 1987
including Summit 1987 Declaration.
/2/ UNEP-GEMS Report: Towards the Design for a Meta-database for the Harmonization of
Environmental Measurement, Report of the Expert Group Meeting, July 26-27, 1990, UNEP -
EARTHWATCH - GEMS Report Series No. 8, June 1991.
/3/ Survey of Environmental Monitoring & Information Management Programmes of
International Organizations, UNEP-HEM, 2nd edition April 1991.
/4/ Crain, I.K.: A Meta-Database for Harmonization of Environmental Measurements,
Discussion Paper for the 1. Expert Group Meeting, July 1990.
/5/ Benking, H.: Information about Environmental Information: Introduction and Preliminary
design considerations, pre-studies, and discussion paper for the 1. International Expert
Group Meeting, February - July 1990.
/6/ Kampffmeyer; U.: Design, Classification and Multi-lingual Thesauri Development Issues
and Concepts related to the Task of Meta-Database Development; 1. UNEPHEM Expert Group
Meeting, July 1990.
/7/ Kampffmeyer, U., Benking, H., Keune, H., Theissen, A.: UNEP-HEM Meta-Database and
Information System HEMIS, Design of HEMIS, Sept. 1991.
/8/ Keune, H., Theisen, A.: Environmental Databases and Information Management Programmes
of International Organizations. In: Hälker, M.; Jaeschke, A. (eds.), Computer Science for
Environmental Protection, Informatik Fachberichte, pp. 546553, Springer, Heidelberg, 1991.
/9/ Gwynne, M.D.: Global Monitoring, Data Management and Assessment within GEMS and GRID;
GEMS/PAC, Nairobi, November 1989.
/10/ Cogels, M.: MDS THESAURUS - The Multilingual Descriptor System for Inventories on the
Environment, (Da Vinci Consulting for the EEA-TF), Brussels, December 1991
/11/ Keune, H; Murray, A.B.; Benking, H.: Harmonization of Environmental Measurement,
GeoJournal, Kluwer, 23.3 249-255, March 1991.
/12/ Benking, H.; Kampffmeyer, U.: Access and Assimilation: Pivotal Environmental
Information Challenges - Linking, Archiving, and Exploring Multi-Lingual and Multi-Scale
Environmental Information Repositories, GeoJournal 24.3, March (1992) (in print).
/13/ Kampffmeyer, U: Deskriptoren versus Volltext, DGD/LID Tagung Frankfurt
"Strategien für Optical Filing - Anwendungen im Pressearchiv". Frankfurt.
November 1991.
Links
Photo & Links (European Net-Homesite)
| Integrity / Ceptual Institute Homepage |